REGARDS processing microservice
Processing architecture
Domain entities
There are five main entities introduced by Processing. Since their names are
rather generic and semantically overloaded, they are prefixed by a P referring
to the "P"rocessing context.
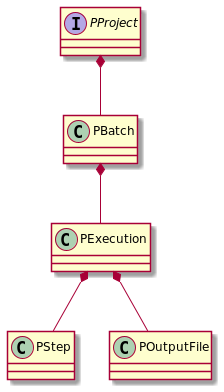
Before describing each of the entities in more details, here is the very crude idea behind this architecture:
- a
PProcessdescribes a program to be run on data, the program can be configured with parameters, - a
PBatchdescribes a logical group of executions of aPProcess, providing values for the program configuration parameters, - a
PExecutiondescribes the launch of the program on data, providing the actual input files, - a
PInputFilethe description of a file to be used during an execution (it is actually a glorified URL pointing to some data), - a
PStepis en event occuring during an execution (flagging the execution as running, in success or in failure), - a
POutputFileis a result of an execution, and may refer to thePInputFiles which were used to build it.
PProcess
At the top of the abstraction hierarchy is the PProcess. A PProcess is the
abstract description of a procedure to be applied to one or many files.
The PProcess has several expected attribute:
- an UUID,
- a name,
- a set of metadata named the "process info".
It also provides more specific attributes:
- a size forecast, allowing to predict before launching execution, the expected quantity of data outputted for a given input size,
- a duration forecast, allowing to predict the expected duration of treatment, allowing to compute a timeout duration for each execution,
- a mapper from output to input, telling how to assign the corresponding inputs to a given output,
- validators for
PBatchandPExecutioncreation using thisPProcess, allowing to decide in advance if the process may be used in a given context, - a workload engine and an executable, describing what and how to run the corresponding program ; these mechanism will be explained below.
PProcess is an interface, and there is a default basic concrete class
ConcretePProcess implementing it as a simple POJO. However, any type of class
could implement PProcess, depending on the final application.
PBatch
A user has data to process, and has chosen a PProcess to treat them.
In order to launch treatments (also called executions), the user must
first acquire a PBatch, by calling the Processing service and providing:
- the
PProcessconfiguration parameter values to be used by all executions - statistics regarding the quantity of data to treat.
This allows the Processing service to decide whether the treatments
can be done or not. For instance, some configuration parameter values might
be wrong, or some quota of use may be reached. This validation is done
using the PProcess batch validator.
If the batch validator accepts the information, it delivers a PBatch
instance, saved in the Processing service database. This batch has:
- an ID,
- a correlation ID given by the user when requesting the creation of the batch, which will be provided for any execution result later,
- the values for the
PProcessparameters which will be used by all the executions launched in the context of this batch.
A batch is an immutable entity: it never changes once it has been created.
Abusing batches is possible
Once the batch has been created and delivered to the user, the user may use
it and abuse it. Theere is for now no limitation of the number of executions
a user can do using the same batch ID. This limitation is not enforced because
sometimes, the input statistics provided at the batch creation may be
slightly inexact, and it is hard to predict in advance how many executions
will be needed to treat all the data. Instead of making bad heuristics,
the choice has been made to trust the user to not abuse the system, especially
since for now the only user for Processing is the Order service, which
has no interest in abusing batches.
However, if Processing had to be accessed directly by end users in the future,
it will require to enforce a more strict policy regarding the execution creation
within a given batch.
PExecution
When the user has received the batch response providing the batch ID, the
user can send execution request to Processing, using an AMQP
PExecutionRequestEvent message.
The execution request contains:
- the batch ID it corresponds to (determining the configuration parameters
for the
PProcess), - the list of
PInputFileto use as input data for this execution, - an execution correlation ID, which will be provided back when
Processingreturns the execution result (as an AMQPPExecutionResultEvent).
When the Processing service receives the request, it validates it using the
PProcess execution validator, and if accepted, saves it in the service
database and then runs it, using the PProcess executable and workload engine.
A Pexecution is a mutable entity: while running the executable, PSteps are
emmitted and added to the PExecution, providing a current status and last update
timestamp for the execution.
PInputFile
A PInputFile is an input file descriptor, defining:
- where the file is located using an URL,
- the file size/content type/checksum,
- a file-specific correlation ID, which will be used when reporting back the execution result, allowing to map output files back to the input file correlation IDs which were used to generate the output file.
A PInputFile is an immutable entity.
PStep
While running in the context of an execution, the process-supplied IExecutable
has access to en event notifier, allowing to inform the Processing service
that steps have occurred in the execution.
A PStep is an immutable entity with the following fields:
- a status defining the type of step (RUNNING, SUCCESS, FAILURE, etc.).
- an optional set of output files used if the step is final.
An execution status can be transitory of final. Final statuses are:
- SUCCESS,
- FAILURE,
- and TIMED_OUT.
Once a final status is reached, the execution is considered finished and
the PExecutionResultEvent is created and sent to the AMQP broker.
POutputFile
When a PStep is final, it is supposed to contain a list of output results,
in the form of POutputFiles.
A POutputFile is, like the PInputFile, a wrapper around an URL. It has:
- an ID,
- a reference to the corresponding execution UUID,
- a file name, URL, size and checksum,
- a list of optional
PInputFilecorrelation IDs, allowing to make reference to the input which generated this output.
The POutputFile is mutable and also has a few technical flags:
downloadedtells if the file has been downloaded by the client,deletedtells if the file has been deleted and is not present for download anymore.
General algorithm
Here is a description of the way a client needs to interact with Processing in order
to launch executions. (Only the 'happy path' is represented.)
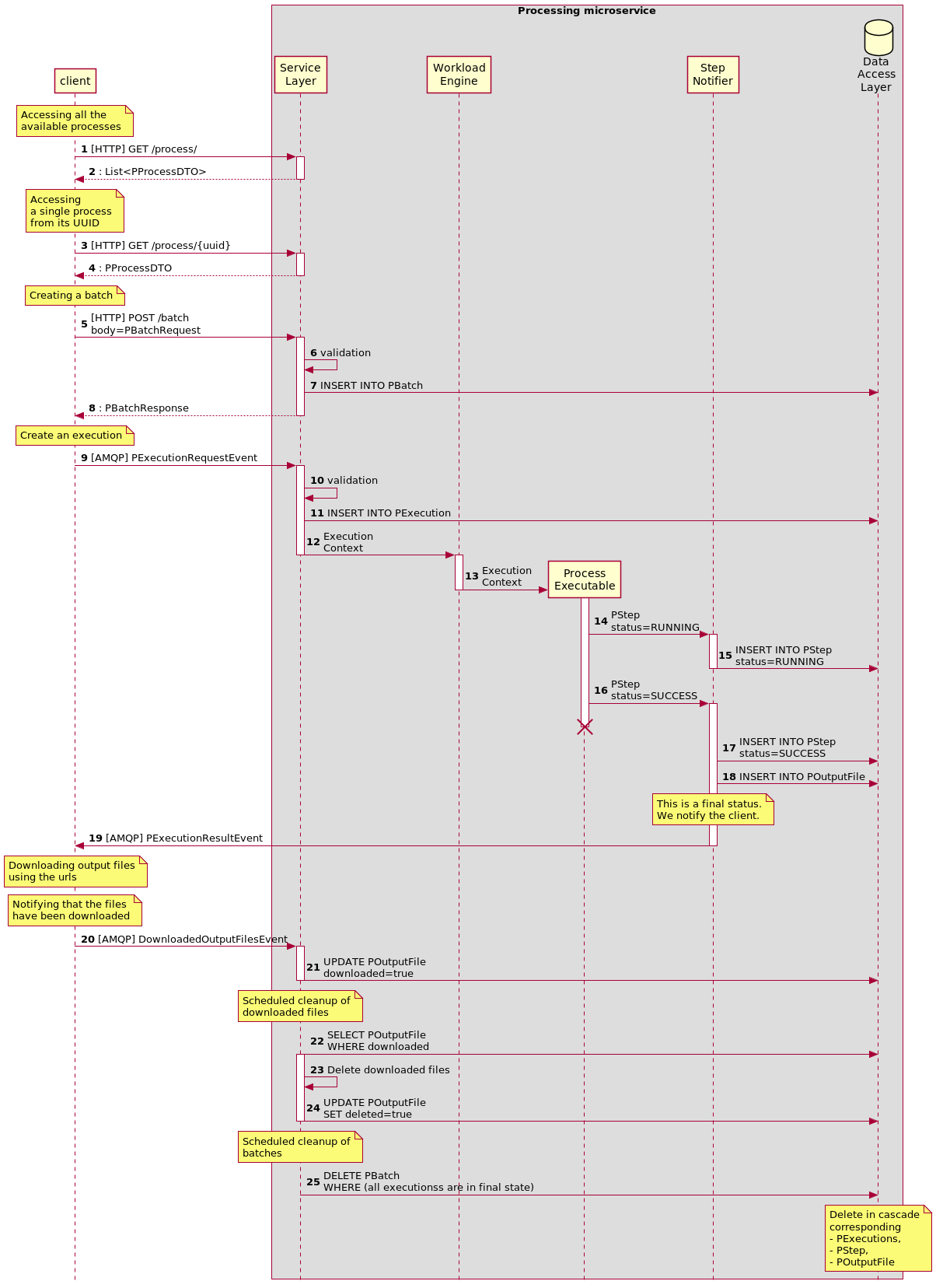
The client needs to interact first with the REST API in order to get the PProcess
details and then create a PBatch.
Then, the user needs to send PExecution requests events through AMQP.
The Processing service then launches the work using the workload engine for
the corresponding process, which launches an executable (provided by the process).
Running the executable generates steps, which are notified using a step notifier present in the execution context which is given to the executable.
When the notifier receives a final step (step with a final ExecutionStatus), it
generates an execution result event sent back to the client though AMQP.
The final step contains references to the output files generated during the
execution. The user is free to download them by whichever means it has. Once
the download is done, the user notifies Processing through AMQP of the
downloaded files. Processing marks them as downloaded.
A scheduled service runs at a given periodicity to take all the output files marked as downloaded, and delete them from the shared storage space where they have been stored, and marks the output files as deleted in the database.
A scheduled service runs at a given periodicity to take all the batches for which all the executions have been finished for a given duration, and deletes them from the database. This deletion cascades to all the executions, steps, and output files linked to this batch.
Technical details
Workload engine / executable / execution context
This section describes the why and how of the workload engine, and the mechanism by which executables notify execution events.
The Processing service is an empty shell. It does not run the processes
itself, but delegates the running to the workload engine referenced by a PProcess.
Generalities on workload engines
The WorkloadEngine responsibility is then to define how the IExecutable
defined by the process will be launched (which could be synchronously,
in a separate thread, in a different virtual machine, etc.).
A WorkloadEngine is a way to abstract the running of processes. It is an
interface to frameworks like REGARDS jobs, Spring Batch, etc. whose purpose
is to launch programs on demand.
A WorkloadEngine instance has a name, and references itself when loaded
at bootstrap in a WorkloadEngineRepository. A PProcess will provide
the name of the engine it is supposed to run on.
When an execution of the PProcess is started, the service will load the
corresponding WorkloadEngine. For instance, in the case of the deployment
of Processsing for launching treatments on orders, the WorkloadEngine used
by all processes is for now based on REGARDS jobs. Launching an execution
with this engine is just creating a LaunchingExecutionJob as QUEUED.
ExecutionEvent
An execution event signifies that something happened during an execution.
The execution event contains an optional PStep (which may be final or not)
and an optional list of POutputFiles. The event can signify that a step
has been reached, or that output files have been generated, or both.
(In the context of the use of Processing for order data treatment, the
processes must send output files only along with a final step, but this
is a limitation given by the context of use, rather than a limitation of
the domain as it is designed.)
IExecutionEventNotifier
The IExecutionEventNotifier interface defines how to deal with events
sent during an execution. It is a simple functional interface which takes
as input an ExecutionEvent and returns a Mono<PExecution>
(with the steps potentially updated with the event step). (The Mono wrapper
signifies that a side-effect has been done during the execution, for instance
a modification of the execution in the database.)
ExecutionContext
An ExecutionContext provides access to:
- the
PProcessandPBatchcorresponding to the execution, - an
IExecutionEventNotifier, - a mutable map of metadata.
IExecutable
An IExecutable is a function which takes as input an ExecutionContext and
returns a Mono<ExecutionContext>. The Mono wrapper signifies that
side effects may occur.
IExecutables are simple functions which can be chained, allowing for
compositionality and modularity. Simple executable steps can be aggregated
into more complex executables.
These functions are meant to do side effects, and use the input ExecutionContext's
event notifier, in order to advance steps or signify that outputs have been
generated.
An IExecutable is not supposed to know anything about the workload engine
that runs it, but it practise some information can be passed by the workload
engine to the executable through the ExecutionContext metadata.
Reactive-first service
The Processing microservice has been identified as a potential bottleneck
with heavy load. Because it might also be often prompted for monitoring
information, the choice has been made to make this microservice with a
reactive stack, using Spring Webflux and Netty as the backbone.
However, in the context of REGARDS, and because there is a lot of security configuration inherited from REGARDS, the service can be (and has been) configured to run in a servlet context, backed by Jetty.
It should be beneficial to the service to remain in a reactive-first
logic, especially in its domain core. The reactive model permeates throughout
the code in the form of function from values to Monos and Fluxes of
values. (Clean code often tends to leave such frameworks out of the
domain, but it is very hard to do so with Reactor ; especially since
the underlying interfaces do not discriminate between single-valued publishers
and multi-valued ones, and typing everything as Publisher is not helpful.)
As for the REST controllers, two versions are provided: a reactive and a servlet one.
Clean architecture
The Processing service is based on 'Clean Architecture' principles.
This means that it has a domain core and several adapters, which abstract away
the different ways to interact with the external world.
The core defines:
- the base entities describes above,
- the interfaces for services and repositories to manage the entities.
The main adapters are:
- database access,
- event handlers,
- process management,
- workload engine.
Database access adapter
This adapter uses a reactive dirver (r2dbc) and is not destined to be reimplemented for another context, unless there is a need to connect to something else than postgresql.
In order to allow Processing to be run effectively in all contexts, and
in order to allow imitations on PProcess, the choice has been made to
use the reactive driver R2DBC to the database.
This allows to use Processing in a reactive context without suffering
from thread-blocking in database calls.
This has several consequences however:
- reactive drivers to databases are bad at relations, which is why the database is de-normalized in several ways, attempts to re-normalize the schema will involve performance costs, and need for way more requests to the database,
- there is a clean border between the domain layer and the data access layer, meaning that there is a need for mapping domain entities to database entities.
In the database access layer, the objects corresponding to domain entities are
BatchEntity, ExecutionEntity, StepEntity (which is actually part of a JSON
field in ExecutionEntity) and OutputFileEntity.
Event handlers
This adapter uses AMQP event handlers reusing the REGARDS IPublisher and IHandler
interfaces. It is reusable as long as the mechanisms behind these interfaces
are available.
Process management
This adapter uses REGARDS plugins as described below. It is not reusable in a different context.
Workload engine
This adapter uses REGARDS jobs as described below. It is not reusable in a different context.
Order specific design choices
The Processing service has a domain core based on a reactive stack and a
clean code architecture. This allows the service to be used in many contexts,
however its main use is in conjunction with the Order service, in the
REGARDS context, and reusing several REGARDS functionalities. This means that
Processing is not used in reactive mode, but in servlet mode, in this context.
OrderProcessInfo, scope and cardinality
A PProcess provides a metadata key/value store, which provides free information
to the user. The author of the process can put any useful information for using
the process in this metadata.
In the case of processes used by Order, this process info is interpreted as
an OrderProcessInfo object, containing:
- limitations on the quantity of data accepted as input,
- the list of required
DataTypefiles (for instance, if a process will be applicable only onRAWDATAfiles, this list contains onlyRAWDATA), - the process size forecast, so that Order can pre-calculate an estimate of the size of the output files
- and two informations we will discuss in more details below: scope and cardinality.
Process scope
The scope tells how to launch executions in the context of the same suborder.
The scope can be any of the two following values:
FEATURE: the process is designed to deal with one feature at a time, and thus there will be one execution per feature in the suborder,SUBORDER: the process is designed to deal with several features at a time, and there will be only one execution per suborder, with all the features given as input.
Process cardinality
The cardinality tells how many output files an execution will generate.
The cardinality can be any of the following values:
-
ONE_PER_INPUT_FILE: the process is designed to produce one output file for each input file.An example of such a process would be a process which produces a companion file for each input file, providing information about the file content, its size, etc.
-
ONE_PER_FEATURE: the process is designed to produce one output file for each feature present in the suborder (this has the same result asONE_PER_INPUT_FILEif there is only one input file per feature, for instance if the process requires only theRAWDATAfiles and each feature has only oneRAWDATA),An example of such a process would be to create a compressed archive for each feature, each archive containing all the files associated to the feature.
-
ONE_PER_EXECUTION: the process is designed to produce only one output file, no matter what its input is.An example of such a process would be to take several images and generate a superposition of all these images, or again producing a compressed archive of all the files present in the input.
Scope/cardinality couples
Since there are 2 scopes and 3 cardinalities, there are 6 possible combinations, but not all of them are meaningful/useful, and there is redundancy.
For instance, the couples:
scope=FEATURE cardinality=ONE_PER_FEATUREandscope=FEATURE cardinality=ONE_PER_EXECUTION
have the same result: the scope says that there is one execution per feature, so they result in the same behaviour.
The other couples are:
scope=FEATURE cardinality=ONE_PER_INPUT_FILE, which may often also have the same behaviour as the couple above, if there is only one file provided as input for each feature (which may be the case if the process requires only theRAWDATAfiles as input),scope=SUBORDER cardinality=ONE_PER_FEATUREis useful if the process is designed to treat features independently but has better performances when grouping several executions, for instance because it has a big overhead in its initialization,scope=SUBORDER cardinality=ONE_PER_INPUT_FILEis useful in the same cases, but now there are several files per feature and they are treated independently,scope=SUBORDER cardinality=ONE_PER_EXECUTIONis useful if the process is designed to aggregate information from several features ; however there is for now no possibility to group features according to criteria in the same suborder, so the process must accept any group of features.
General algorithm of Order/Processing interaction
Here is a description of the way Order and Processing interact, leaving the
details of the Processing inner working out of the picture for more clarity.
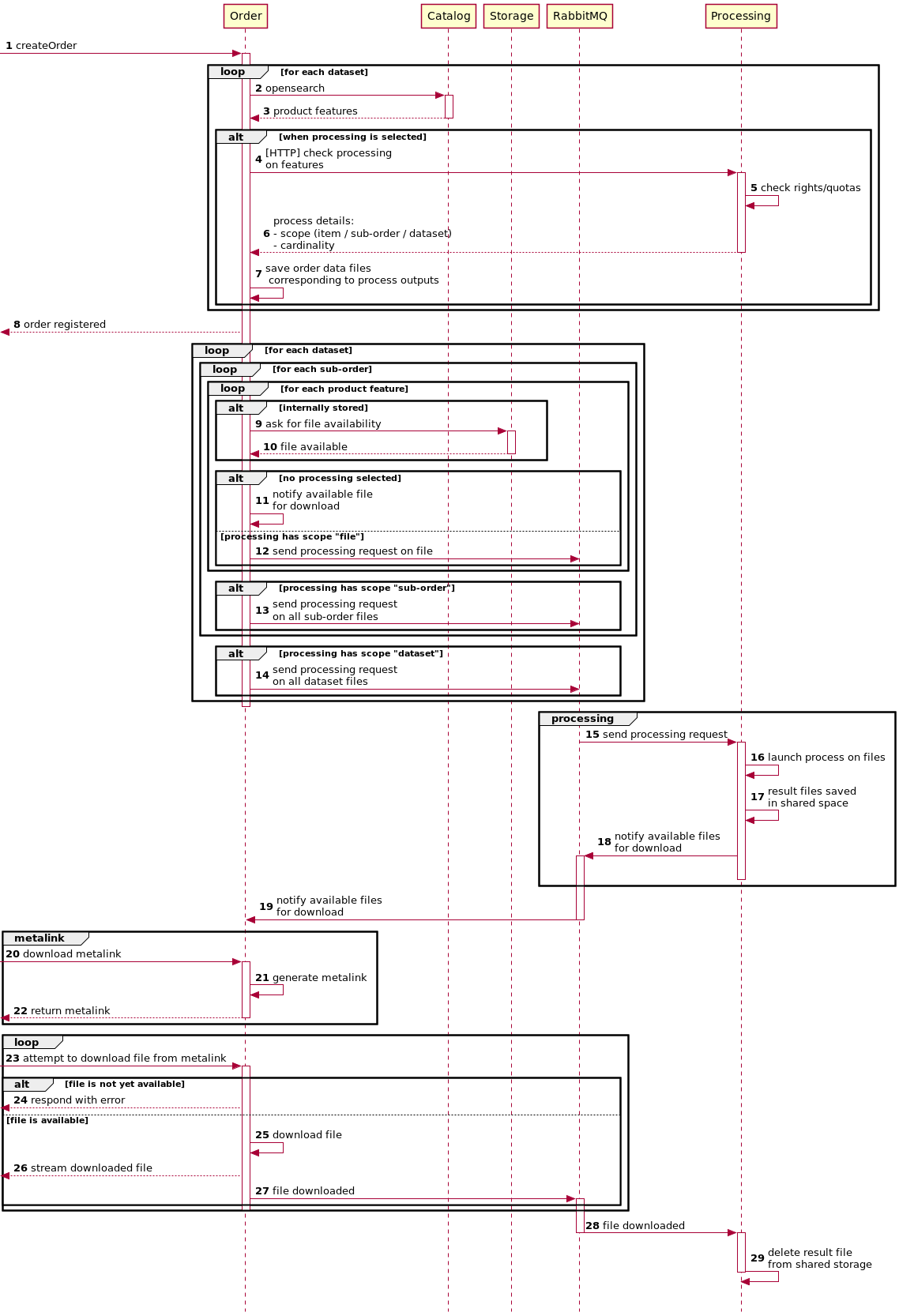
Process definitions are REGARDS Plugins
In the context of the Processing service deployed in REGARDS along with the
Order service, where processes are used to post-process entity feature files,
processes are defined as REGARDS plugins, implementing the IProcessDefinition
interface.
These plugins need some configuration:
- allowed dataset for a process
- allowed user role to use a process
This extra information is stored in database as a wrapper for
PluginConfiguration named RightsPluginConfiguration. There is a specific
REST API for interacting with these wrappers, which are used by the
administrator.
Workload engine uses REGARDS Jobs
The provided workload engine uses the REGARDS jobs mechanism. When the workload engine is given an executable, it creates a QUEUED job for execution as soon as possible.
By setting the regards.jobs.pool.size property, we can limit the number
of jobs running in parallel, and thus the number of process executions. This limits
the overall number of jobs, however, and thus does not permit to limit the number
of executions per process.