Dynamic collections
L'implémentation STAC de REGARDS permet une navigation hiérarchique à travers les collections dynamiques, sous forme d'un arbre de collections à plusieurs niveaux, basé sur des attributs extraits des données.
Un niveau dans l'arbre des collections dynamiques correspond ainsi à un attribut des données utilisé pour partitionner à la volée le catalogue.
- Chaque noeud de l'arbre est une collection dynamique, générée automatiquement
- Chaque niveau représente un critère différent
Par exemple, en configurant notre plugin avec les trois niveaux de recherche suivant :
- Niveau 1 : satellite
- Niveau 2 : instrument
- Niveau 3 : date d'ingestion
On obtiendra un arbre de recherche de cette forme :
└── Sentinel-2
└── MSI
├── 2022
└── 2023
└── SPOT-6
└── HRG
├── 2021
└── 2023
La structure est définie par configuration du plugin STAC.
Attention, il existe deux endroits dans l'IHM de configuration du plugin STAC où il est possible de configurer la structure de l'arbre des collections dynamiques :
- La configuration du STAC datetime property
- La configuration des différents attributs dans le tableau des STAC properties
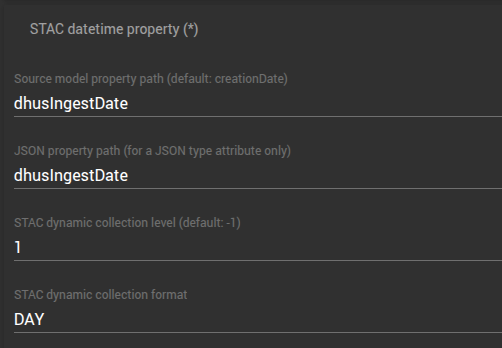
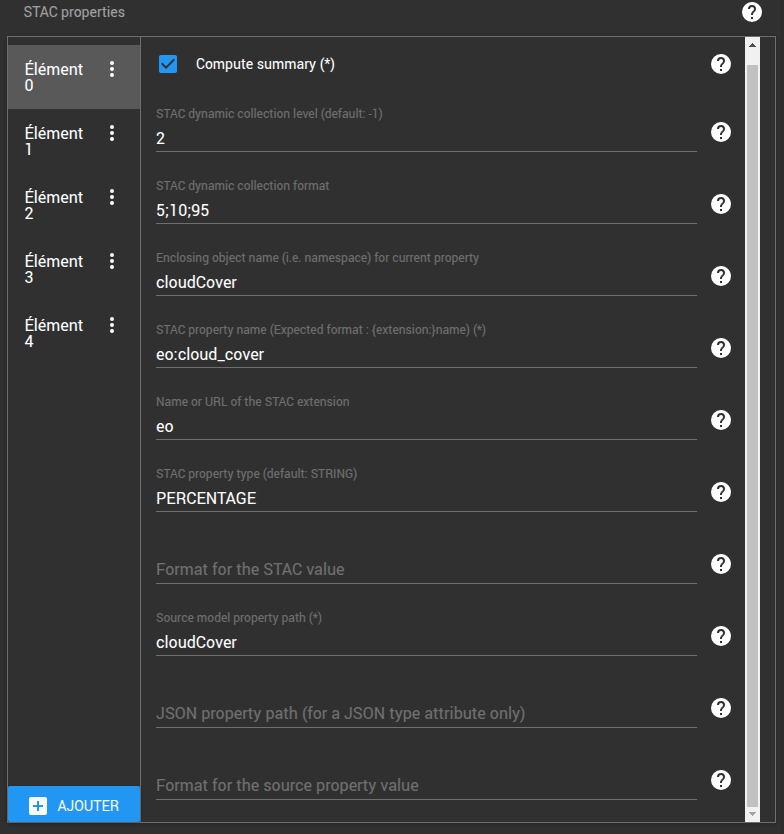
Pour pouvoir utiliser l'attribut d'un modèle de donnée comme niveau de recherche dans l'arbre de collections dynamiques, il faut que cet attribut soit configuré comme recherchable ("indexed=true") dans le modèle de données de REGARDS.
Configuration du niveau dans l'arbre des collections dynamiques
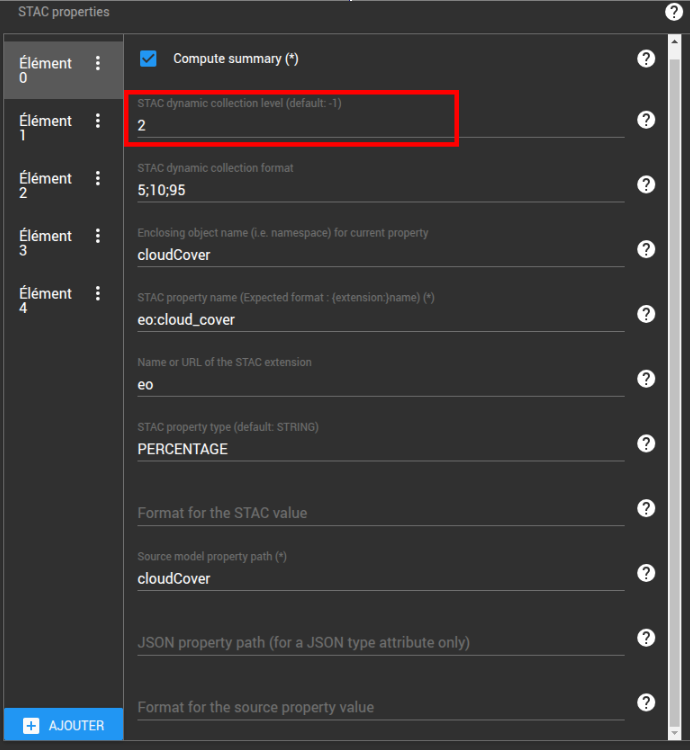
Cette valeur définit le niveau au sein de l'arbre de la propriété à laquelle elle est rattachée. Si cette valeur est positive, la valeur est utilisée pour afficher l'attribut au niveau spécifié, comme décrit précédemment.

Si le champ est vide ou a une valeur négative, le champ est ignoré, l'attribut ne sera alors pas utilisé pour structurer l'arbre de recherche.
La valeur par défaut de ce champ est -1.
Chaque attribut configuré doit avoir propre niveau au sein de l'arbre des collections dynamiques. Si plusieurs attributs sont au même niveau, l'ordre des collections dynamiques n'est pas garanti.
Format des valeurs proposées dans les collections dynamiques
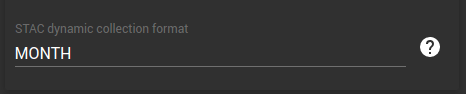
Cet attribut permet de spécifier le format d'une collection dynamique. Pour un même attribut, différents niveaux de précision peuvent être utilisés afin de restreindre plus ou moins finement les collections et les données associées, en fonction de la valeur attribuée au paramètre Format.
Les formats sont :
- Pour les dates :
YEAR|MONTH|DAY|HOUR|MINUTE, pour les type d'attributDATETIME - Pour les nombres :
MIN;INTERVAL;MAX, pour les typesNUMBER, ou tout autre type basé sur des nombres (ANGLE,LENGTH,PERCENTAGE). Par exemple,5;10;95 - Pour préfixer les chaines de caractères de type
STRING:PREFIX(X,Y)avec :Xun nombre number andYestA,9ouA9. Par exemple,PREFIX(3,A9))
- Les autres types STAC sont traités comme si le format était
EXACT.
Format EXACT
Ce format indique que l’utilisateur peut naviguer dans l’arborescence des collections dynamiques en fonction de la valeur exacte de la propriété présente dans les documents.
Par exemple, si l’attribut choisi est satellite et qu’il ne prend que deux valeurs possibles (SPOT5 et Sentinel-2),
alors une propriété dynamique de type EXACT produira deux sous-niveaux distincts dans l’arborescence :
satellite=SPOT5satellite=Sentinel-2
En raison de l'absence de pagination dans le standard STAC pour les collections, l’utilisation d’un attribut en mode EXACT doit être réservé aux cas où celui-ci ne possède qu’un nombre limité de valeurs distinctes — idéalement quelques dizaines tout au plus.
Les administrateurs doivent veiller à ne pas appliquer ce format à des attributs trop discriminants (comme un identifiant unique par document), sous peine de dégrader fortement les performances de l’API.
Type Datetime
Un attribut de type datetime peut être configuré avec différents niveaux de précision temporelle, en choisissant l’une
des valeurs suivantes :
YEARMONTHDAY(valeur par défaut)HOURMINUTE
Ce paramètre détermine la profondeur de l’arborescence temporelle générée dans les collections dynamiques.
Exemple : format configuré à HOUR
Si l’administrateur choisit le format HOUR, l’arborescence se décomposera en quatre niveaux hiérarchiques :
- Année : L’utilisateur peut d’abord sélectionner une année parmi celles disponibles
datetime=2020datetime=2021- etc.
- Mois : Ensuite, les mois disponibles pour l’année choisie sont proposés
datetime=2021-01datetime=2021-02- ...
datetime=2021-12
- Jour : Puis, les jours disponibles pour le mois sélectionné :
datetime=2021-02-01datetime=2021-02-02- ...
datetime=2021-02-28
- Heure : Enfin, les heures disponibles pour le jour choisi sont listées
datetime=2021-02-07T00datetime=2021-02-07T01- ...
datetime=2021-02-07T23
Chaque niveau permet ainsi un affinage progressif de la recherche temporelle jusqu’au niveau d’heure.
Type Number
Pour les attributs numériques, il est possible de configurer un format basé sur une plage de valeurs, en utilisant
la syntaxe suivante : MIN;INTERVAL;MAX.
Les valeurs sont séparées par des points-virgules et permettent de définir des tranches numériques pour organiser
les collections dynamiques.
Cette configuration génère automatiquement :
- une collection regroupant toutes les valeurs inférieures au minimum (<
MIN) - une collection pour chaque intervalle régulier de taille
INTERVAL, entreMINetMAX - une collection regroupant toutes les valeurs supérieures au maximum (>
MAX)
Par exemple, pour l'attribut eo:cloud_coverage, l'administrateur pourrait configurer le format 5;10;95.
Cette configuration produira les collections suivantes :
eo:cloud_coverage < 55 < eo:cloud_coverage < 1515 < eo:cloud_coverage < 25- ...
85 < eo:cloud_coverage < 95eo:cloud_coverage > 95
Les administrateurs doivent apporter une configuration qui ne génère pas trop d'intervalles, quelques dizaines au maximum.
Type String
Les propriétés de type String peuvent être structurées dynamiquement par préfixe, afin de créer une arborescence de collections basée sur les premiers caractères de la chaîne.
Le format s’écrit PREFIX(X,Y), défini comme ceci :
X: le nombre de caractères du préfixe à utiliserY[A|9|A9]: le type de caractère à considérer[A]: uniquement les caractères alphabétiques (de A à Z)[9]: uniquement les caractères numériques (0 à 9)[A9]: les caractères alphabétiques et numériques
Par exemple, si l’administrateur configure l’attribut country avec : PREFIX(2,A), cela générera deux niveaux
hiérarchiques dans les collections dynamiques :
- Premier niveau – sur la première lettre du nom du pays :
country=A...country=B...- ...
country=Z...
- Deuxième niveau – sur les deux premières lettres :
country=FA...country=FB...- ...
country=FZ...
Ce mécanisme permet une navigation par regroupement lexical progressif, utile pour les champs comme les pays, les identifiants, les codes produit, etc.